Objectives
The objectives of this section are:
to explain the K-Means clustering algorithm
to introduce its limitations
to examine the various major parts
Outcomes
By the time you have completed this section you will be able to:
briefly explain the K-Means clustering algorithm
list the major steps in the algorithm
Assignment step
In order to determine which centroid is closest to a particular data point we have to use a proximity measure. There are several proximity measures in use and typically one is chosen based on the data type that we are trying to cluster. Manhattan, Euclidean, cosine and Bregman divergence are all proximity measures that help us determine which cluster a point should be assigned to. The Euclidean is commonly used.
Re-estimation step
Re-calculating the centriod is tied to the goal of the clustering algorithm and the proximity measure that is being used. The goal of the clustering algorithm is otherwise known as the objective function and once it has been defined, the centroid can be calculated mathematically. When our objective is to minimize the sum of the squared L2 distance of an object to its cluster centriod we use the sum of the squared error (SSE). The SSE basically calculates for each point the distance from that point to the nearest cluster and then squares it and adds up the sum for all points in the dataset. The equation is shown below.
x is a data point in cluster Ci and mi is the representative point for cluster Ci
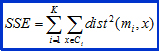
The K-means algorithm tries to minimize this value for each set of centriods that is given for that iteration.

