Objectives
The objectives of this section are:
briefly introduce various measures used to evaluate clusters, clustering types and clustering algorithms
Outcomes
By the time you have completed this section you will be able to:
list various methods used to in the evaluation stage of cluster analysis
Introduction
Clustering is an unsupervised learning algorithm and because of this the evaluation measures and methods used are different and a little bit trickier than for classification models.
For starters, how would you define a good cluster? What looks like a good cluster to you might look like a potato to me. How would one compare the results of a clustering technique to the results of another? How do you determine if the data presented is random or in fact a cluster? These are just a couple of questions that immediately come to mind. Cluster evaluation is more commonly referred to as cluster validation and this might just be because it has many layers and facets. Cluster validation can be unsupervised or supervised.
Unsupervised
This ties heavily into the nature itself of clustering algorithm which is an unsupervised learning tool. It does not really on any external information to help rate or evaluate the clusters. They are also called internal indices and this is because they use information that is readily available in the data set.
Evaluation Using Cohesion and Separation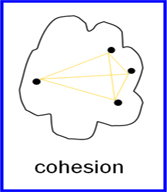
Cluster cohesion: these measures determine how closely related the objects in a cluster are. For instance an unsupervised cluster evaluator that measured cohesion could analyze the distance between the data points in cluster A(Figure 1).
Cluster Separation: these measures determine how distinct a cluster is from other clusters. This is more concerned with the distance between cluster A below and cluster B as shown in Figure 2 below.
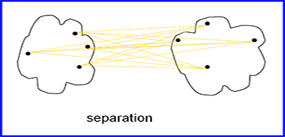
One thing to note is that cohesion and separation vary according to the type of cluster. In section 1 we briefly mentioned the various types of clusters that can be used and for each of their type’s cohesion and separation are defined differently. Figures 1 and 2 above represent the graph-based view of clusters and cannot be generalized and used for all cluster types.
Evaluation Using the Proximity Matrix
An alternative way to evaluate a cluster is to use its proximity matrix. This can be done by visualization or by comparing actual and idealized proximity matrices to each other. Figure 3 below shows three well separated clusters and Figure 4 is the corresponding similarity matrix sorted by K-means cluster labels. The disadvantage of an approach like this is that the computation of the proximity matrix is expensive especially for large data sets.
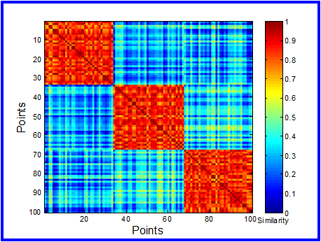
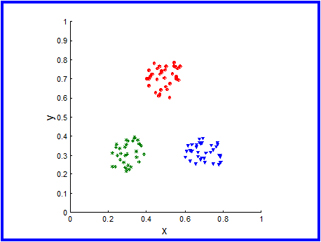
Supervised
Measures how well the clustering algorithms’ created structure matches to some external data. For instance, if we already knew the class labels for a given set of data we could use a clustering algorithm to group the data and then compare these clusters to the labels that were given. This requires external data and so it is otherwise known as external indices because it uses information that is not in the data set.
This is almost the same as evaluation of classifiers discussed in chapter 1. Some common measures include
Entropy: measures the degree to which each cluster consists of objects of a single class.
Purity: is similar to entropy in that it also measures the degree of homogeneity of each cluster
Precision: this is the fraction of a cluster that consists of objects of a specified class.
Recall: on the other hand is the extent to which a cluster contains all objects of a specified class.
In summation this is just an introduction to cluster validation; the validation aspect of clustering analysis is the most complex yet crucial part of the system. For more information consult a tradition Data Mining textbook.

