Objectives
The objectives of this section are:
to explain the K-Means clustering algorithm
to introduce its limitations
to examine the various major parts
Outcomes
By the time you have completed this section you will be able to:
briefly explain the K-Means clustering algorithm
list the major steps in the algorithm
Definition
K-means is one of the oldest and most commonly used clustering algorithms. It is a prototype based clustering technique defining the prototype in terms of a centroid which is considered to be the mean of a group of points and is applicable to objects in a continuous n-dimensional space.
Description
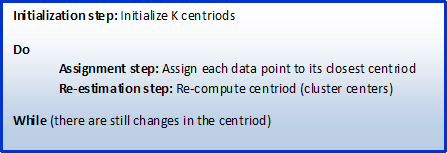
The K-means algorithm involves randomly selecting K initial centroids where K is a user defined number of desired clusters. Each point is then assigned to a closest centroid and the collection of points close to a centroid form a cluster. The centroid gets updated according to the points in the cluster and this process continues until the points stop changing their clusters. A high-level representation of the K-means algorithm is shown in Figure 1.
Initialization step: Choosing Initial Centroid
Randomly: different runs of the algorithm can produce poor results when the initial centriods are choosing randomly. It is important to realize that the choice of the initial centroid has a huge effect on the final result, for instance the figure below shows the resulting clusters based on two different randomly selected centroids. As one can see, the bottom left image is a more accurate representation.
Solutions to this problem
- Multiple Runs: To perform multiple runs, each with a different set of randomly chosen initial centriods and then selects the set of clusters with the minimum SSE. The problem with this method is that it doesn’t always work.
- Take a sample of points and cluster them using a hierarchical clustering technique and then K clusters are extracted from this clustering and the centriods are then used as the initial centriods for the K-means algorithm. The downside to this method is that it is only works if the sample is relatively small and K is relatively small in comparison to the sample size.
- Select the first point at random for the first centroid and then for all other initial centriods (k-1) select a point that is farthest from any of the initial centroids that have already been selected. By doing this we obtain a set of initial centroids that is randomly selected and separated. The down side to this method is that we could end up selecting an outlier as a centroid.
- Upgrading the algorithm and using the bisecting K-means algorithm which is less susceptible to initialization issues.

