Objectives
The objectives of this section are:
to introduce you to alternative ways of evaluating the performance of a classifier based on a test set.
Outcomes
By the time you have completed this section you will be able to:
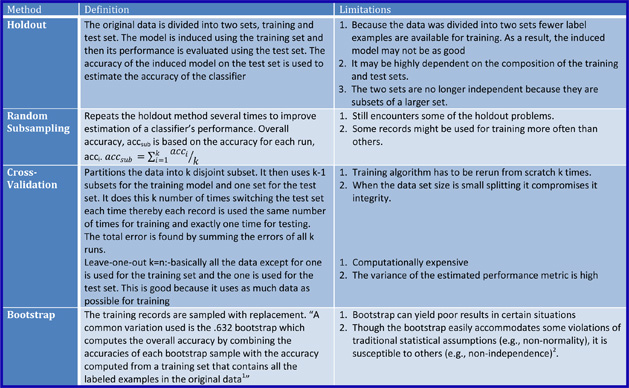
to explain the holdout method
to describe the random subsampling method
to differentiate between the traditional cross-validation and leave-out-one approach
to define the bootstrap method
Evaluating the Performance of a Classifier
The previous section introduced you to the two major types of errors that we can encounter when dealing with Decision Trees. Training errors which are influenced by overfitting can be estimated in a number of ways that were also introduced in Section 4. Test errors which are as a result of applying the model to a set not previously used to construct the classifier are helpful because they provide an unbiased estimate of the generalization error. In this section you will be introduced to methods used to evaluate the performance of a classifier using test data.
There is a catch. Initially, you are only given one set of data to work with, the training data. You are not given any test data that already has been classified. So we have to find a way to evaluate the classifier on test data which has its label. Now you might think that the best way to address this issue is just to create two subsets from the original data set, use one for training and creating the classifier and the other for testing but this reduces the amount of data we have to help create the classifier thereby sacrificing some accuracy. There are four main methods presented in this section that aim to solve this problem while provided a suitable alternative for evaluating with test data. The table below describes these methods and some limitations involved in using them.