Objectives
The objectives of this section are:
to introduce you to the concept of classifications
to impart on you its usefulness in our society
to awaken you to the boundless applications
to excite you to delve deeper into the world of data mining
Outcomes
By the time you have completed this section you will be able to:
describe what classification is
determine when classification can be used
and distinguish between the two main models presented
What is Classification
Definition
Classification is the ability to group data based on their attributes, when you see a person with grey hair, wrinkles and a walking stick your brain classifies them as a senior citizen almost instantly, the goal of classification is to mirror this behavior for computer systems. In data mining classification deals with grouping items into various predefined categories based on a list of attributes or characteristics provided.
Predictive Modeling
Predictive modeling is one of the two main branches of data modeling, the other being descriptive modeling. As the name suggests, it involves creating a model that helps predict the outcome (class) of an item based on the attributes it has. Its goal is to identify strong links between variables x in order to determine the y value they map too.
Data classification is a predictive model and has a two step process, the first step is known as the training phase or learning step and it involves using a classification algorithm to build a classifier. The training data is used to create the classifier; this information includes complete items that have already been classified. Table 1 below is an example of the training data that can be used to help create a classifier that determines whether a person will attend a political town hall meeting based on their political party, household income, location and voting history.
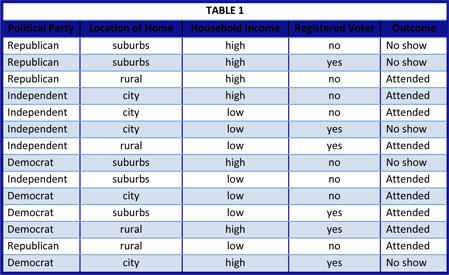
The second step known as the testing phase deals with accuracy. This is very important because we are able to verify how well the classifier model works. The model that has been created in the first step is evaluated by using test data that is not part of the training data (previously used in the first step) to judge the accuracy of the classifier. The accuracy of the classifier is estimated by computing an error based on the difference between the predicted value (obtained from using the model) and the actual known value (which is part of the test data). Table 2 below is an example of test data that can be used on the classifier model to help determine its accuracy. Calculation of the error is discussed in later sections

Applications
Some applications of classification include
- Predicting tumor cells as benign or malignant
- Classifying credit card transactions as legitimate or fraudulent
- Categorizing news stories as finance, weather, entertainment, sports, etc.
- Detecting spam email messages based upon the message header and content
- Classifying galaxies based upon their shapes.

